Precision Ontology. Purposeful AI.
The right context for your AI agents. Memory that knows your business.
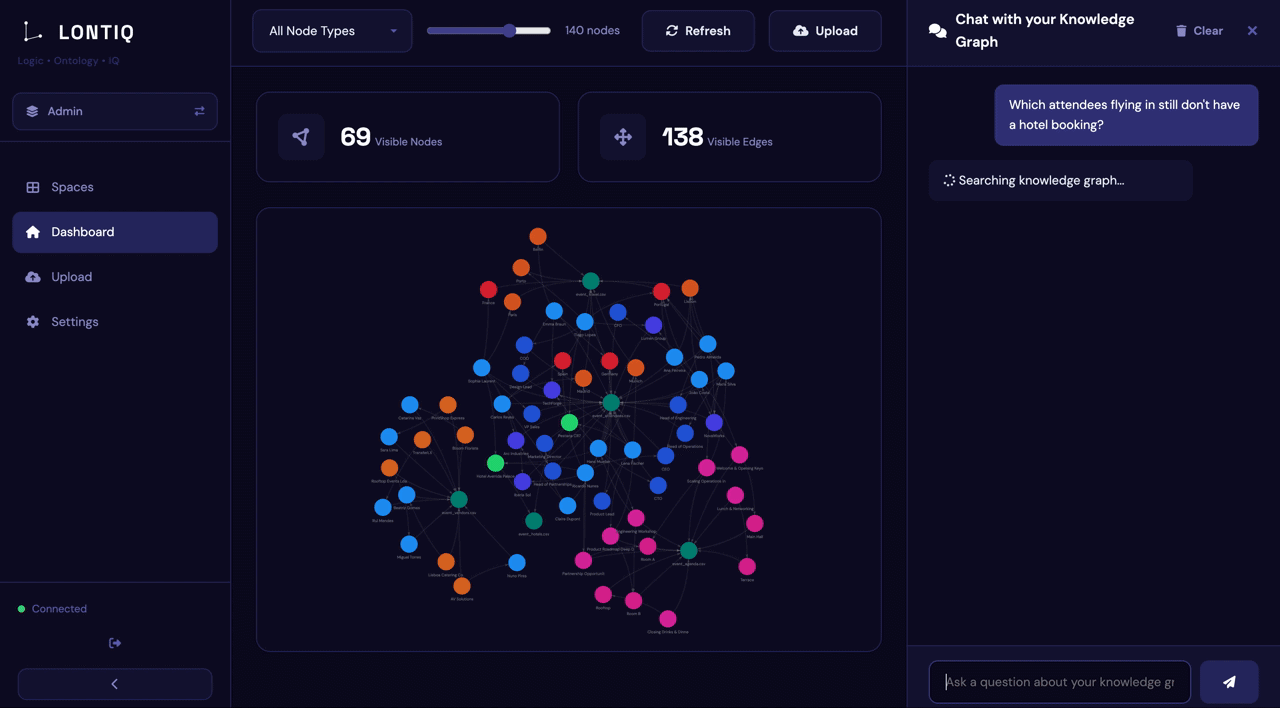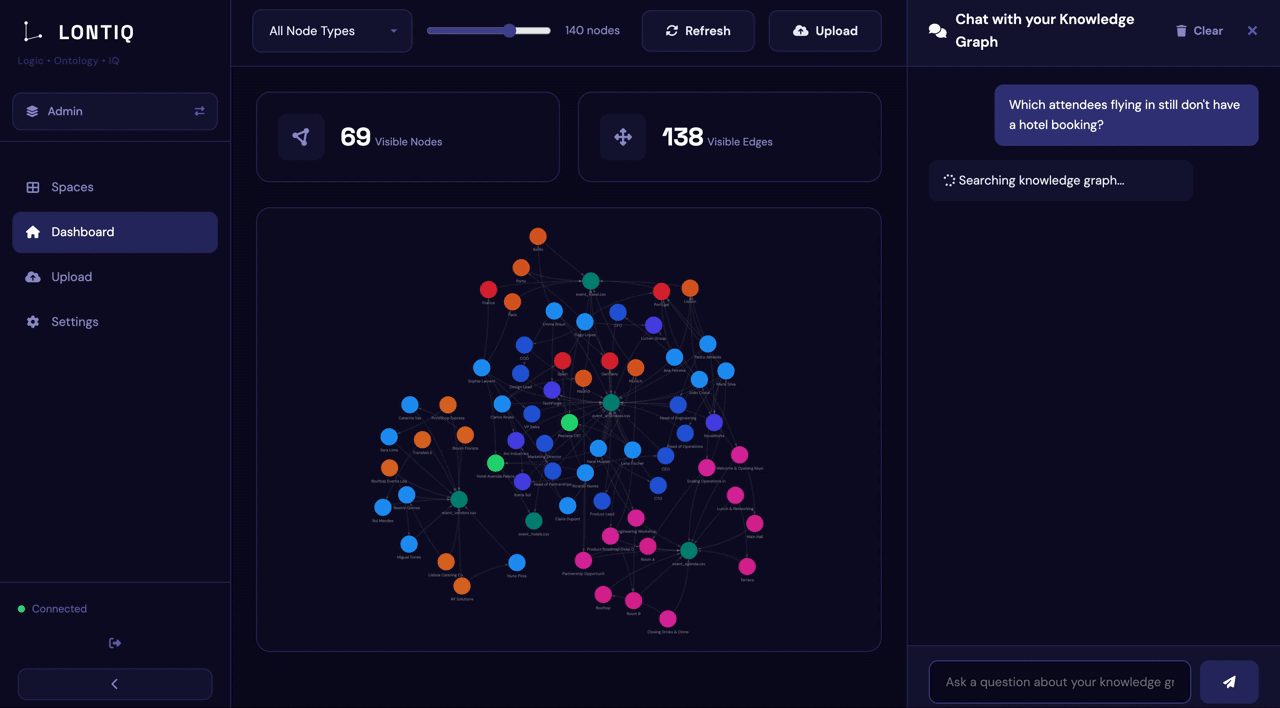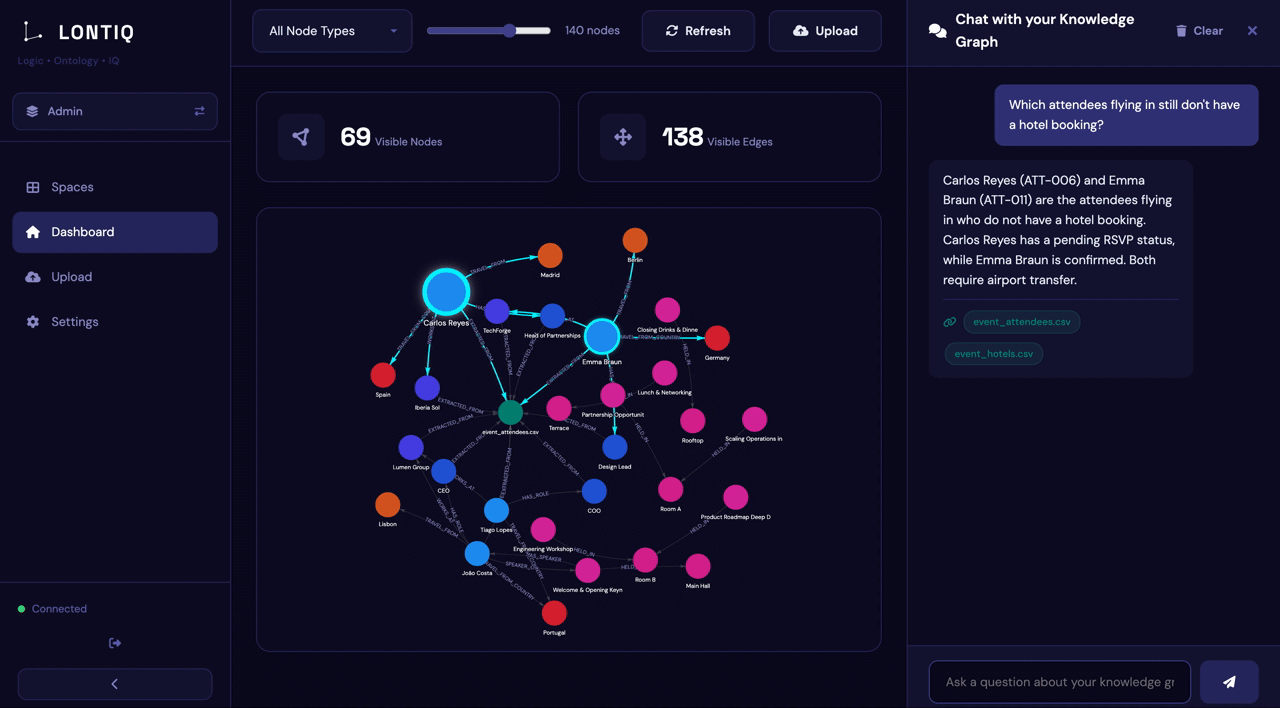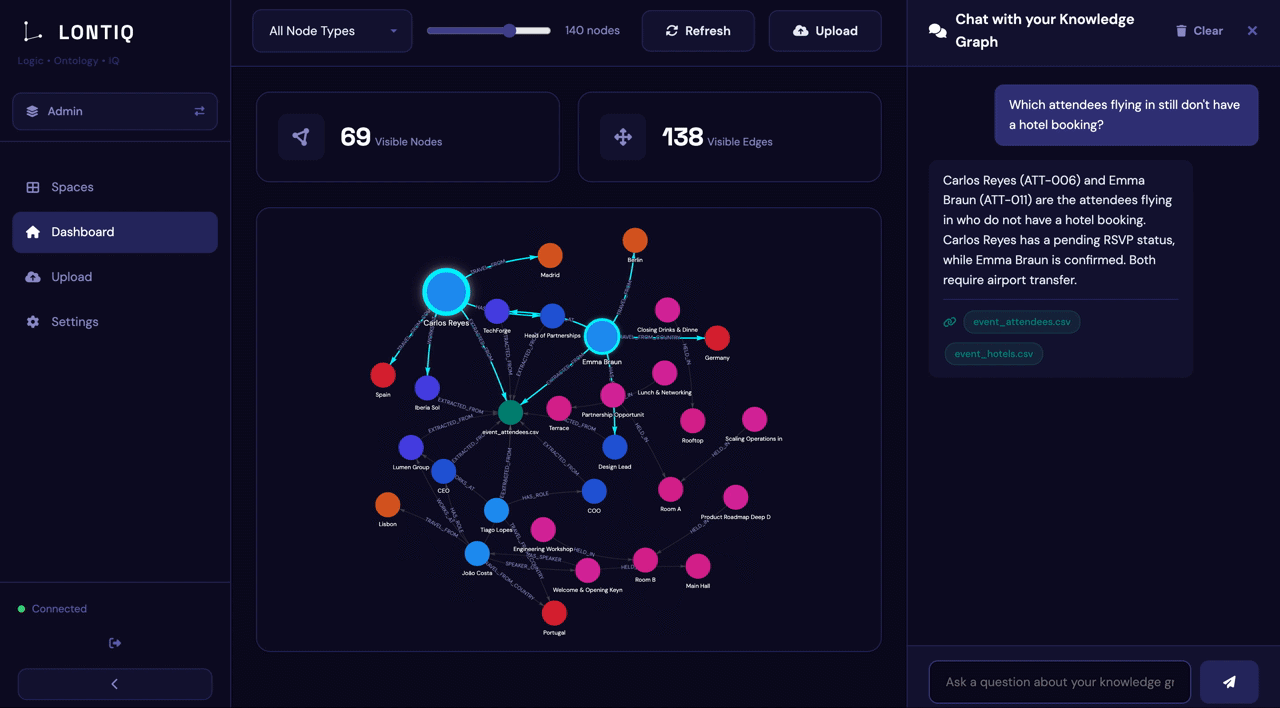
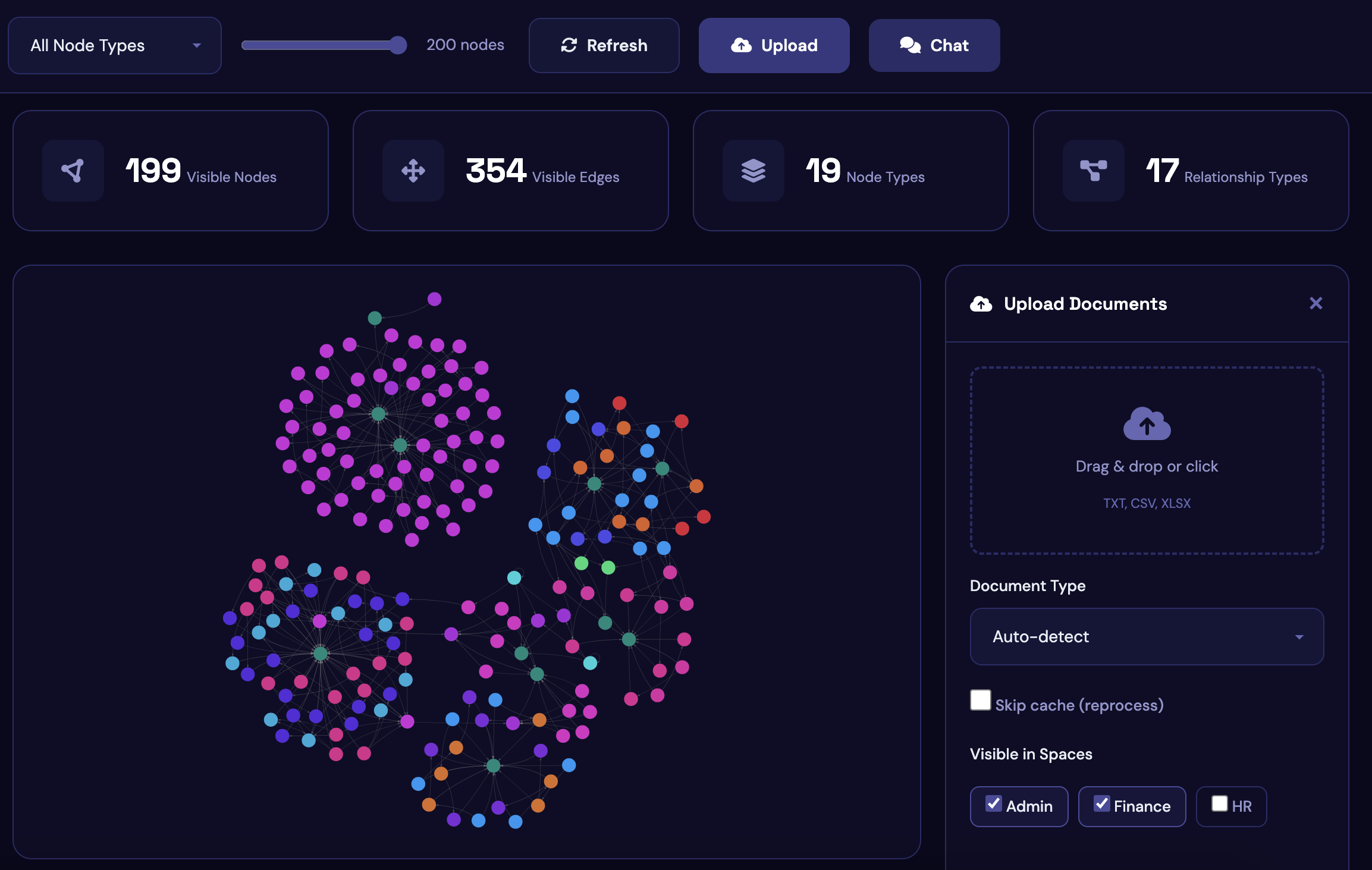
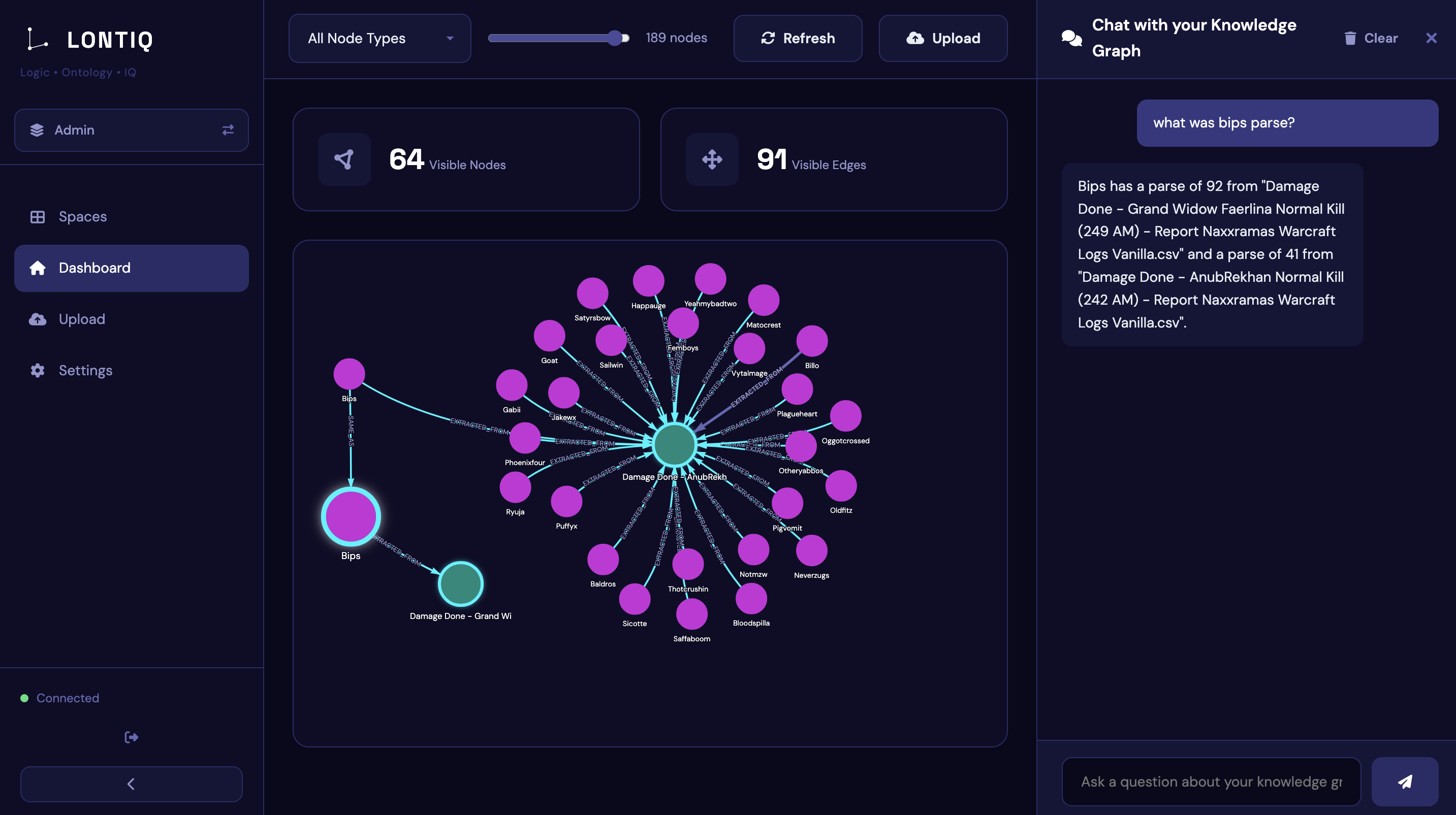
Turn your company's data and files into a structured knowledge graph your agents, copilots, and LLMs can query directly with every answer traceable back to the source.